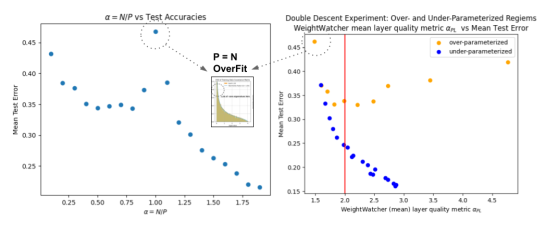
Double Descent (DD) is something that has surprised statisticians, computer scientists, and deep learning practitioners–but it was known in the…
Thoughts on Data Science, Machine Learning, and AI
Double Descent (DD) is something that has surprised statisticians, computer scientists, and deep learning practitioners–but it was known in the…

Recently, Microsoft Research published the LASER method: ”Layer-Selective Rank Reduction” in this recent, very popular paper The Truth is in There:…

Recently, the Mistral models have taken the LLM world by storm. The Mistral Mixture of Experts (MOE) 8x7b model outperforms other…

Evaluating LLMs is hard. Especially when you don’t have a lot of test data.In the last post, we saw how to…
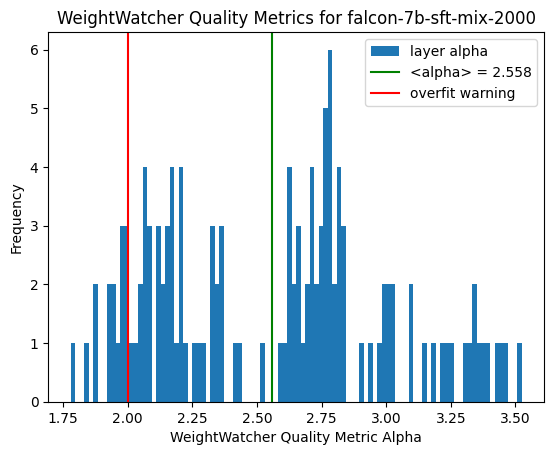
if you are fine-tuning your own LLMs, you need a way to evaluate them. And while there are over a dozen…

WeightWatcher 0.7 has just been released, and it includes the new and improved advanced feature for analyzing Deep Neural Networks…
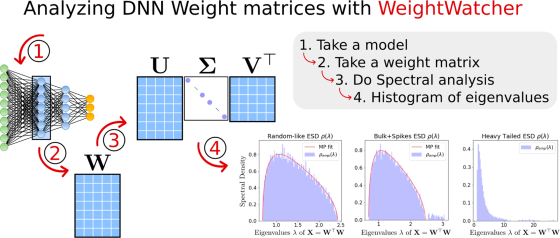
First, let me say thanks to all the users in our great community — we have reached over 93K downloads…

AI has taken the world by storm. With recent advances like AlphaFold, Stable Diffusion, and ChatGPT, Deep Neural Networks (DNNs)…

Have you ever had to sort through HuggingFace to find your best model ? There are over 54,000 models on…

Say you are training a Deep Neural Network (DNN), and you see your model is over-trained. Or just not performing…
